
Publications
Improving Image-Based Localization by Active Correspondence Search
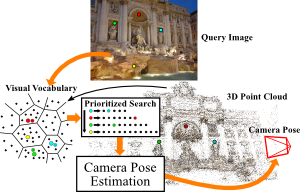
We propose a powerful pipeline for determining the pose of a query image relative to a point cloud reconstruction of a large scene consisting of more than one million 3D points. The key component of our approach is an efficient and effective search method to establish matches between image features and scene points needed for pose estimation. Our main contribution is a framework for actively searching for additional matches, based on both 2D-to-3D and 3D-to-2D search. A unified formulation of search in both directions allows us to exploit the distinct advantages of both strategies, while avoiding their weaknesses. Due to active search, the resulting pipeline is able to close the gap in registration performance observed between efficient search methods and approaches that are allowed to run for multiple seconds, without sacrificing run-time efficiency. Our method achieves the best registration performance published so far on three standard benchmark datasets, with run-times comparable or superior to the fastest state-of-the-art methods.
The original publication will be available at www.springerlink.com upon publication.
Image Retrieval for Image-Based Localization Revisited
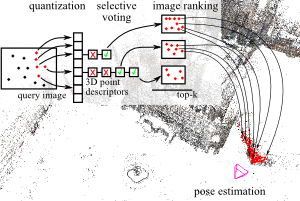
To reliably determine the camera pose of an image relative to a 3D point cloud of a scene, correspondences between 2D features and 3D points are needed. Recent work has demonstrated that directly matching the features against the points outperforms methods that take an intermediate image retrieval step in terms of the number of images that can be localized successfully. Yet, direct matching is inherently less scalable than retrieval-based approaches. In this paper, we therefore analyze the algorithmic factors that cause the performance gap and identify false positive votes as the main source of the gap. Based on a detailed experimental evaluation, we show that retrieval methods using a selective voting scheme are able to outperform state-of-the-art direct matching methods. We explore how both selective voting and correspondence computation can be accelerated by using a Hamming embedding of feature descriptors. Furthermore, we introduce a new dataset with challenging query images for the evaluation of image-based localization.
Towards Fast Image-Based Localization on a City-Scale
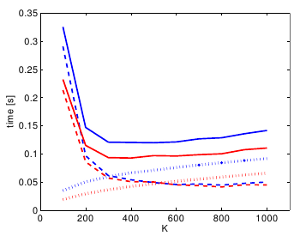
Recent developments in Structure-from-Motion approaches allow the reconstructions of large parts of urban scenes. The available models can in turn be used for accurate image-based localization via pose estimation from 2D-to-3D correspondences. In this paper, we analyze a recently proposed localization method that achieves state-of-the-art localization performance using a visual vocabulary quantization for efficient 2D-to-3D correspondence search. We show that using only a subset of the original models allows the method to achieve a similar localization performance. While this gain can come at additional computational cost depending on the dataset, the reduced model requires significantly less memory, allowing the method to handle even larger datasets. We study how the size of the subset, as well as the quantization, affect both the search for matches and the time needed by RANSAC for pose estimation.
The original publication will be available at www.springerlink.com upon publication.
Fast Image-Based Localization using Direct 2D-to-3D Matching

Estimating the position and orientation of a camera given an image taken by it is an important step in many interesting applications such as tourist navigations, robotics, augmented reality and incremental Structure-from-Motion reconstruction. To do so, we have to find correspondences between structures seen in the image and a 3D representation of the scene. Due to the recent advances in the field of Structure-from-Motion it is now possible to reconstruct large scenes up to the level of an entire city in very little time. We can use these results to enable image-based localization of a camera (and its user) on a large scale. However, when processing such large data, the computation between points in the image and points in the model quickly becomes the bottleneck of the localization pipeline. Therefore, it is extremely important to develop methods that are able to effectively and efficiently handle such large environments and that scale well to even larger scenes.
