
Welcome







The research and teaching activities at our institute focus on geometry acquisition and processing, on interactive visualization, and on related areas such as computer vision, photo-realistic image synthesis, and ultra high speed multimedia data transmission.
In our projects we are cooperating with various industry companies as well as with academic research groups around the world. Results are published and presented at high-profile conferences and symposia. Additional funding sources, among others, are the Deutsche Forschungsgemeinschaft and the European Union.
News
| • |
We have a paper on learning fine-to-coarse cuboid shape abstraction at Eurographics 2026. |
Feb. 25, 2026 |
| • |
We have a paper on layout optimization at Eurographics 2026. |
Feb. 24, 2026 |
| • |
Our papers Quantised Global Autoencoder: A Holistic Approach to Representing Visual Data and Bijective Feature-Aware Contour Matching received best paper award and best presentation award respectively, at the 30th VMV 2025. |
Oct. 7, 2025 |
| • |
We have a paper on improved visual data generation at ICCV 2025. |
Oct. 6, 2025 |
| • |
We have a paper on retargeting visual data at ECCV 2024. |
Aug. 5, 2024 |
| • |
We have a paper on freeform shape fabrication at Eurographics 2024. |
April 26, 2024 |
Recent Publications
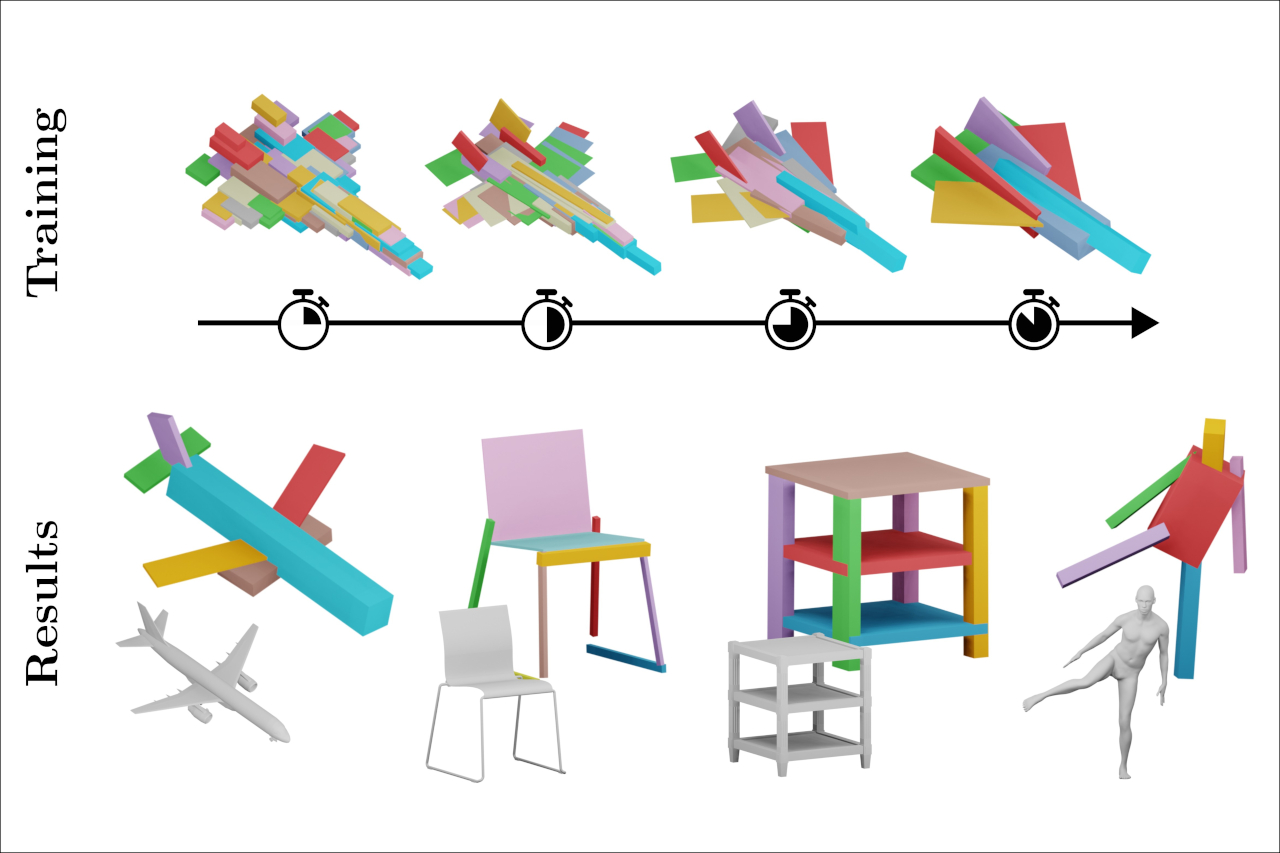 Self-supervised Learning of Fine-to-Coarse Cuboid Shape Abstraction Eurographics 2026 The abstraction of 3D objects with simple geometric primitives like cuboids allows us to infer structural information from complex geometry. It is important for 3D shape understanding, structural analysis and geometric modeling. We introduce a novel fine-to-coarse self-supervised learning approach to abstract collections of 3D shapes. Our architectural design allows us to reduce the number of primitives from hundreds (fine reconstruction) to only a few (coarse abstraction) during training. This allows our network to optimize the reconstruction error and adhere to a user-specified number of primitives per shape while simultaneously learning a consistent structure across the whole collection of data. We achieve this through our abstraction loss formulation which increasingly penalizes redundant primitives. Furthermore, we introduce a reconstruction loss formulation to account not only for surface approximation but also volume preservation. Combining both contributions allows us to represent 3D shapes more precisely with fewer cuboid primitives than previous work. We evaluate our method on collections of man-made and humanoid shapes comparing with previous state-of-the-art learning methods on commonly used benchmarks. Our results confirm an improvement over previous cuboid-based shape abstraction techniques. Furthermore, we demonstrate our cuboid abstraction in downstream tasks like clustering, retrieval, and partial symmetry detection 
|
 Embedding Optimization of Layouts via Distortion Minimization Eurographics 2026 Given an embedding of a layout in the surface of a target mesh, we consider the problem of optimizing the embedding geometrically. Layout embeddings partition the surface into multiple disk-like patches, making them particularly useful for parametrization and remeshing tasks, such as quad-remeshing, since these problems can then be solved on simpler subdomains. Existing methods can either not guarantee to maintain patch connectivity, limiting downstream applications, or are specialized for quad layout optimization, relying on principal curvature information. We propose a framework that balances per-patch distortion minimization with strict connectivity control through an explicit representation. By inserting additional nodes along layout arcs, they can be embedded as piecewise geodesic curves on the surface. This sampling of arcs provides additional flexibility where required, enabling joint optimization of both node positions and arc embeddings. Our representation naturally supports a multi-resolution workflow: optimization on coarse meshes can be prolongated to high-resolution inputs. We demonstrate its effectiveness in applications requiring connectivity-preserving, low-distortion surface layouts.
|
 Multidimensional Byte Pair Encoding: Shortened Sequences for Improved Visual Data Generation International Conference on Computer Vision, ICCV 2025 In language processing, transformers benefit greatly from text being condensed. This is achieved through a larger vocabulary that captures word fragments instead of plain characters. This is often done with Byte Pair Encoding. In the context of images, tokenisation of visual data is usually limited to regular grids obtained from quantisation methods, without global content awareness. Our work improves tokenisation of visual data by bringing Byte Pair Encoding from 1D to multiple dimensions, as a complementary add-on to existing compression. We achieve this through counting constellations of token pairs and replacing the most frequent token pair with a newly introduced token. The multidimensionality only increases the computation time by a factor of 2 for images, making it applicable even to large datasets like ImageNet within minutes on consumer hardware. This is a lossless preprocessing step. Our evaluation shows improved training and inference performance of transformers on visual data achieved by compressing frequent constellations of tokens: The resulting sequences are shorter, with more uniformly distributed information content, e.g. condensing empty regions in an image into single tokens. As our experiments show, these condensed sequences are easier to process. We additionally introduce a strategy to amplify this compression further by clustering the vocabulary.
|
