
Profile

|
Yanjiang He, M. Sc. |
Publications
Self-supervised Learning of Fine-to-Coarse Cuboid Shape Abstraction
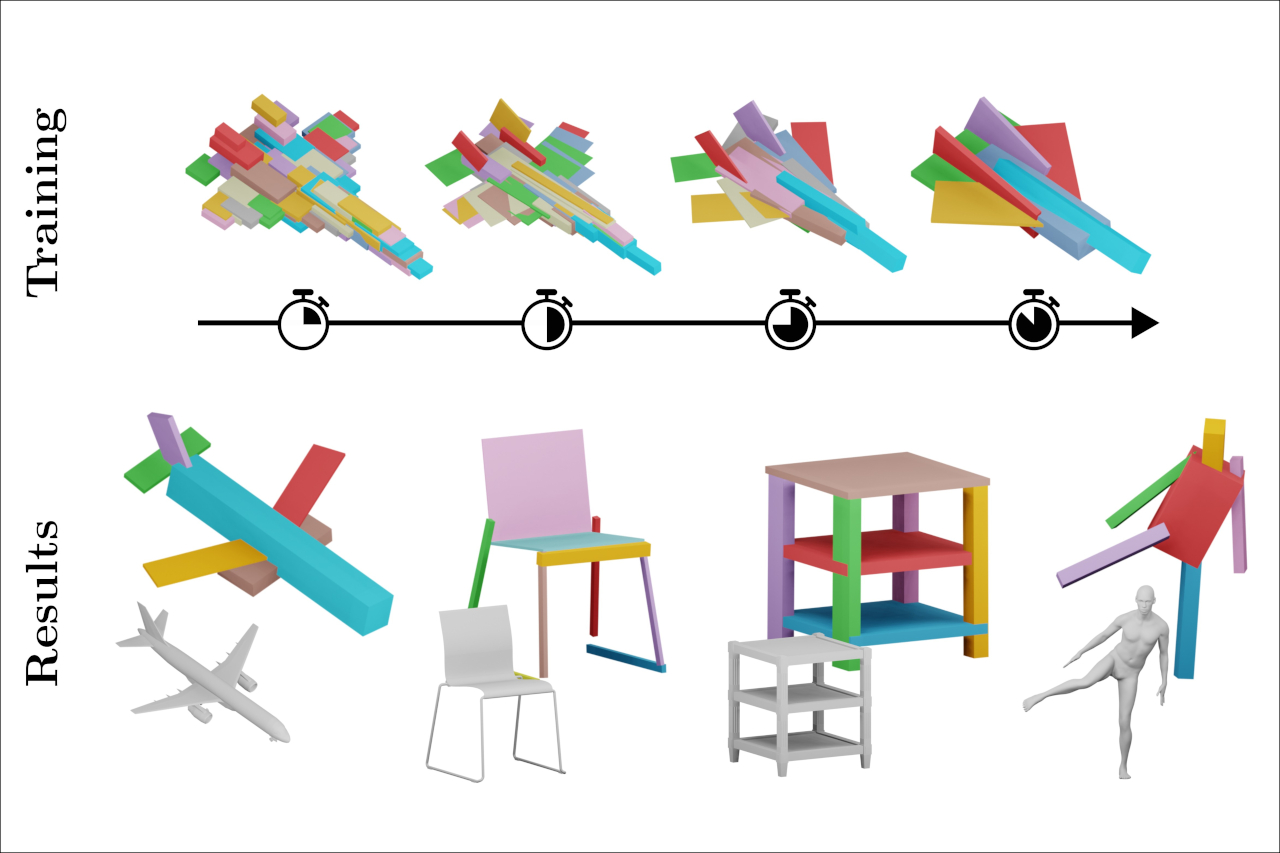
The abstraction of 3D objects with simple geometric primitives like cuboids allows us to infer structural information from complex geometry. It is important for 3D shape understanding, structural analysis and geometric modeling. We introduce a novel fine-to-coarse self-supervised learning approach to abstract collections of 3D shapes. Our architectural design allows us to reduce the number of primitives from hundreds (fine reconstruction) to only a few (coarse abstraction) during training. This allows our network to optimize the reconstruction error and adhere to a user-specified number of primitives per shape while simultaneously learning a consistent structure across the whole collection of data. We achieve this through our abstraction loss formulation which increasingly penalizes redundant primitives. Furthermore, we introduce a reconstruction loss formulation to account not only for surface approximation but also volume preservation. Combining both contributions allows us to represent 3D shapes more precisely with fewer cuboid primitives than previous work. We evaluate our method on collections of man-made and humanoid shapes comparing with previous state-of-the-art learning methods on commonly used benchmarks. Our results confirm an improvement over previous cuboid-based shape abstraction techniques. Furthermore, we demonstrate our cuboid abstraction in downstream tasks like clustering, retrieval, and partial symmetry detection
@article{kobsik2026cuboid,
title={Self-supervised Learning of Fine-to-Coarse Cuboid Shape Abstraction},
author={Kobsik, Gregor and Henkel, Morten and He, Yanjiang and Czech, Victor and Elsner, Tim and Lim, Isaak and Kobbelt, Leif},
year={2026},
journal={Computer Graphics Forum},
volume={45},
number={2},
}
Multidimensional Byte Pair Encoding: Shortened Sequences for Improved Visual Data Generation

In language processing, transformers benefit greatly from text being condensed. This is achieved through a larger vocabulary that captures word fragments instead of plain characters. This is often done with Byte Pair Encoding. In the context of images, tokenisation of visual data is usually limited to regular grids obtained from quantisation methods, without global content awareness. Our work improves tokenisation of visual data by bringing Byte Pair Encoding from 1D to multiple dimensions, as a complementary add-on to existing compression. We achieve this through counting constellations of token pairs and replacing the most frequent token pair with a newly introduced token. The multidimensionality only increases the computation time by a factor of 2 for images, making it applicable even to large datasets like ImageNet within minutes on consumer hardware. This is a lossless preprocessing step. Our evaluation shows improved training and inference performance of transformers on visual data achieved by compressing frequent constellations of tokens: The resulting sequences are shorter, with more uniformly distributed information content, e.g. condensing empty regions in an image into single tokens. As our experiments show, these condensed sequences are easier to process. We additionally introduce a strategy to amplify this compression further by clustering the vocabulary.
Quantised Global Autoencoder: A Holistic Approach to Representing Visual Data

In quantised autoencoders, images are usually split into local patches, each encoded by one token. This representation is redundant in the sense that the same number of tokens is spend per region, regardless of the visual information content in that region. Adaptive discretisation schemes like quadtrees are applied to allocate tokens for patches with varying sizes, but this just varies the region of influence for a token which nevertheless remains a local descriptor. Modern architectures add an attention mechanism to the autoencoder which infuses some degree of global information into the local tokens. Despite the global context, tokens are still associated with a local image region. In contrast, our method is inspired by spectral decompositions which transform an input signal into a superposition of global frequencies. Taking the data-driven perspective, we learn custom basis functions corresponding to the codebook entries in our VQ-VAE setup. Furthermore, a decoder combines these basis functions in a non-linear fashion, going beyond the simple linear superposition of spectral decompositions. We can achieve this global description with an efficient transpose operation between features and channels and demonstrate our performance on compression.
Awards:
@inproceedings{10.2312:vmv.20251231,
booktitle = {Vision, Modeling, and Visualization},
editor = {Egger, Bernhard and Günther, Tobias},
title = {{Quantised Global Autoencoder: A Holistic Approach to Representing Visual Data}},
author = {Elsner, Tim and Usinger, Paula and Czech, Victor and Kobsik, Gregor and He, Yanjiang and Lim, Isaak and Kobbelt, Leif},
year = {2025},
publisher = {The Eurographics Association},
ISBN = {978-3-03868-294-3},
DOI = {10.2312/vmv.20251231}
}
